Di hate speech si è scritto molto negli ultimi anni, non solo i n Italia. Non si tratta di un nuovo campo di studi: ciò che oggi chiamiamo hate speech rientrava prima ne l novero degli studi sul razzismo e la discriminazione. E da quasi una tr entina d’anni abbiamo strumenti e letture che ci permettono di capire come, e quando, il linguaggio attivi – o rispecchi – il cosid detto razzismo “ordinario” (everyday racism), non necessariamente diramatosi dal razzismo istituzionale o (pseudo)scientifico.
Le novità principali degli studi degli ultimi anni però sono al meno tre, e tutte rilevanti: la richiesta di un’attenzione definitoria che permetta di interrogarsi, e possibilmente di intendersi, su che cosa sia lo hate speech, a partire da una sua definizione non soltanto legale ma anche linguistica; l’inclusione, nell’analisi, di nuove modalità e nuovi canali di diffusione, a cominciare dai social media; la possibilità di raccogliere una mole di dati sempre più ampia per sostenere l’analisi qualitativa con una solida base quantitativa, con la crescente consapevolezza che l’una senza l’altra non possono darci le risposte che cerchiamo.
Sul piano della definizione, facciamo così più attenzione non so lo a non confondere hate speech con hate crime, come prevede da alcuni anni il linguaggio giuridico, ma anche ad osser vare dati non puramente lessicali, tentando di costruire una griglia di valutazione multilivello, che tenga insieme parole chiave (o spia) e sematici, frequenza di termini isolati e contesti (quella che in linguistic a chiamiamo prosodia semantica), hate words ed elementi testuali, retorici, pragmatici.
Riguardo ai social media, molte osservazioni utili e importanti sono state fatte in anni recenti sulla specificità degli ambienti online e virtuali rispetto a quelli o ffline, non per cercare un rapporto di causa-effetto (i social come origine dello hate speech), vista l ’abbondanza di linguaggi d’odio anche in diacronia, e nelle interazioni offline, ma per capir e se e come l’online abbia modificato lo hate speech in termini di produzione (Chi lo produce? A quale scopo? Quando?), diffusione, ricezione.
Proprio dall’analisi dei social abbiamo da alcuni anni ricavato s empre più dati, per mezzo di filtri automatici piuttosto rigidi all’inizio (il termine spia in isol amento, senza tener conto dei contesti d’uso e del suo valore pragmatico) e poi grazie ad algoritmi sempr e più avanzati, con cui condurre sentiment analysis, raffinare la raccolta lessicale (eliminando ad esempio occorr enze casuali o non pertinenti), e incrociare i vari livelli linguistici.
Grazie a uno sviluppo pluriennale, tanto sul piano della progettazione quanto sul piano dell’analisi, al focus su un social specifico (Twitter), ovvero alla coerenza metodologica e di costituzione del corpus dei dati, e a una visualizzazione che evidenzi i nessi t ra approccio quantitativo (le statistiche, le percentuali) e qualitativo (i picchi, le mappe termografiche e la g eolocalizzazione), la Mappa dell’Intolleranza 4.0 offre una efficace, esemplare sintesi dello stato di avanzamento dei lavori sullo hate speech. Sia fornendo alcune solide risposte sia offrendo nuove prospettive di ricerca per Twitter e per i social in genere certamente, ma anche per l’offline.
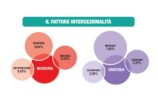
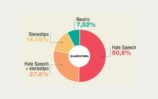
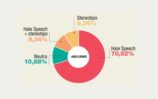
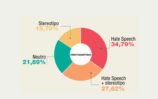
Le sei grosse macroaree (donne, migranti, islamici, omossessuali, ebrei, disabili) riguardano i gruppi quantitativamente più bersagliati da hate speech (ed hate crime), e permettono di confrontare i dati raccolti nel 2019 con quelli provenienti dalle rilevazioni dei 3 anni precedenti. Si individuano così trend di medio periodo (l’odio verso le donne e i migranti) e diff erenze che impongono approfondimenti qualitativi, come l’aumento dei tweet antisemiti. N on solo. Con l’affinamento dei filtri lessicali, per mezzo di algoritmi sempr e più precisi e funzionali, i 76 termini spia relativi alle macroaree vengono considerati solo in contesti pertinenti (per far e un esempio: se troia non è insulto verso una donna, ma ha funzione disfemica come in “porca troia” non viene più raccolto dal software), e quindi le word cloud che ne visualizzano la frequenza relativa permettono considerazioni meno impressionistiche. Come ad esempio, sempre a proposito della macroarea sulle donne, quelle relative alle co-occorrenze di termini come “troia”, appunto, e “tacchi”, “colpa”, “complimenti”, “minigonna”, a fare ipotizzare come trigger del linguaggio d’odio la presenza di un certo abbigliamento o di comportamenti che un codice culturale machista bolla come provocatori o istigatori. Una analisi sempre più attenta delle co-occorrenze e della prosodia semantica ci aiuterà a comprendere sempre meglio lo hate speech oltre le hate words, il contesto testuale oltre il singolo elemento lessicale. E quindi ad interrogarci, funzionalmente, sulla definizione linguistica di linguaggio d’odio.
Relativamente all’ambiente online, la Mappa dell’Intolleranza 4.0 fornisce strumenti e possibilità di lettura imprescindibili, ormai, da una analisi multi-ambientale dello hate speech. Non parlo solo delle mappe termografiche, collaudate da tempo e in grado di geo localizzare le concentrazioni più alte di linguaggio d’odio. Parlo soprattutto della r elazione tra picchi di produzione e circolazione ed eventi offline. Non siamo ancora in grado – e forse è un bene, pe r non cadere nel determinismo – di ragionare in termini di causa-effetto tra online e offline (un certo picco è stata la risposta a un certo evento, o ha anticipato l’accadere di un certo evento), ma siamo in condizione di interr ogarci sugli “sciami” d’odio, e sul loro sviluppo carsico: l’emersione di certo discorso intor no a un evento o alla sua esposizione mediatica, o il consolidamento di un clima d’od io – di cui il linguaggio è certamente una spia considerevole – che determina non una maggiore incidenza del crimine d’odio, ma che accompagna una sua minore stigmatizzazione nel discorso. Siamo cioè in condizione di formulare ipotesi in presenza di dati certi, e di corrispondenze non casuali tra onlin e e offline. Cosa che, senza progetti come Mappa dell’Intolleranza 4.0 non saremmo in grado di fare.
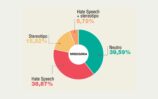
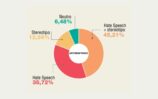
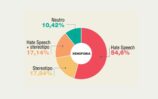
Molto, certo, rimane da fare: sul piano linguistico, l’analisi qualitativa va condotta oltre il livello puramente lessicale, e la visualizzazione in word cloud deve essere completata da carotaggi di prosodia semantica che ci dicano di più, ad esempio, non soltanto sui termini spia presi a campione, ma anche sui verbi a cui sono più frequentemente associati (per interrogarci ad esempio su chi fa che cosa nel testo, sulla agency concessa alle vittime, ecc.) e sull’aggettivazione più frequente, per verificare l’emersione di nuovi pattern sostantivo-aggettivo. Senza contare che l’analisi della prosodia semantica ci permetterebbe di incrociare ancora di più i dati linguistici delle sei macroaree (ad esempio sommando i campi semantici donna+migrante, o migrante+disabile, ecc.). Ma la quantità davvero importante di dati raccolti, attraverso filtraggi sempr e più precisi e specifici, l’individuazione di tendenze o scarti nel medio periodo, e l’an alisi incrociata di online e offline, concentrandosi su un singolo ambiente (Twitter, in questo caso) per poi confrontare i riscontri con quelli ottenuti su altri ambienti (Facebook, ad esempio), come si sta tentando di fare unendo le letture della Mappa dell’Intolleranza 4.0 e Barometro dell’odio 2.0, ci sta già permettendo di avere, in Italia, una banca dati estesa ed affidabile. E un insieme di l etture e di interpretazioni sempre meno impressionistiche su un fenomeno in continuo mutamento, che richiede strumenti ed expertise di monitoraggio adeguati non solo ai flussi, ma anche al cr escente professionismo degli haters e all’affinarsi delle loro strategie.
Ci stiamo insomma attrezzando, finalmente, non solo per descrizione di lunga durata, solida, multilivello, non solo per un’analisi complessa e articolata, m a anche – attraverso una comprensione sempre più evoluta del fenomeno, e al consolidamento di community interdisciplinari e nazionali di ricerca – per un contrasto sempre meno frammentato e più robusto hate speech, tanto online quanto offline.